How to work with a neural network. Neural networks: types, principle of operation and scope. What are neural networks for?
Accordingly, the neural network takes two numbers as input and should give another number at the output - the answer. Now about the neural networks themselves.What is a neural network?

A neural network is a sequence of neurons connected by synapses. The structure of the neural network came to the world of programming straight from biology. Thanks to this structure, the machine acquires the ability to analyze and even memorize various information. Neural networks are also capable of not only analyzing incoming information, but also reproducing it from their memory. Those interested should definitely watch 2 videos from TED Talks: Video 1 , Video 2). In other words, a neural network is a machine interpretation of the human brain, which contains millions of neurons that transmit information in the form of electrical impulses.
What are neural networks?
For now, we will consider examples on the most basic type of neural networks - this is a feedforward network (hereinafter referred to as FDN). Also in subsequent articles, I will introduce more concepts and tell you about recurrent neural networks. SRL, as the name implies, is a network with a serial connection of neural layers, in which information always flows in only one direction.What are neural networks for?
Neural networks are used to solve complex problems that require analytical calculations similar to what the human brain does. The most common applications of neural networks are:Classification- distribution of data by parameters. For example, a set of people is given as input and you need to decide which of them to give a loan and who not. This work can be done by a neural network, analyzing such information as: age, solvency, credit history, etc.
Prediction- the ability to predict the next step. For example, the rise or fall of stocks, based on the situation in the stock market.
Recognition- currently, the widest application of neural networks. Used in Google when you search for a photo or in phone cameras when it detects the position of your face and highlights it and more.
Now, to understand how neural networks work, let's take a look at its components and their parameters.
What is a neuron?

A neuron is a computational unit that receives information, performs simple calculations on it, and passes it on. They are divided into three main types: input (blue), hidden (red) and output (green). There is also a bias neuron and a context neuron, which we will talk about in the next article. In the case when the neural network consists of a large number of neurons, the term layer is introduced. Accordingly, there is an input layer that receives information, n hidden layers (usually no more than 3) that process it, and an output layer that displays the result. Each of the neurons has 2 main parameters: input data (input data) and output data (output data). In the case of an input neuron: input=output. In the rest, the total information of all neurons from the previous layer gets into the input field, after which it is normalized using the activation function (for now, just imagine it f (x)) and gets into the output field.

Important to remember that neurons operate with numbers in the range or [-1,1]. But how, you ask, then handle numbers that are out of this range? At this point, the easiest answer is to divide 1 by that number. This process is called normalization and it is very commonly used in neural networks. More on this a little later.
What is a synapse?

A synapse is a connection between two neurons. Synapses have 1 parameter - weight. Thanks to him, the input information changes when it is transmitted from one neuron to another. Let's say there are 3 neurons that pass information to the next one. Then we have 3 weights corresponding to each of these neurons. For the neuron with the greater weight, that information will be dominant in the next neuron (an example is color mixing). In fact, the set of neural network weights or the weight matrix is a kind of brain of the entire system. It is thanks to these weights that the input information is processed and turned into a result.
Important to remember that during the initialization of the neural network, the weights are randomized.
How does a neural network work?

In this example, a part of a neural network is depicted, where the letters I denote the input neurons, the letter H denotes the hidden neuron, and the letter w denotes the weights. It can be seen from the formula that the input information is the sum of all input data multiplied by their corresponding weights. Then we will give input 1 and 0. Let w1=0.4 and w2 = 0.7 The input data of neuron H1 will be the following: 1*0.4+0*0.7=0.4. Now that we have the input, we can get the output by plugging the input into the activation function (more on that later). Now that we have the output, we pass it on. And so, we repeat for all layers until we reach the output neuron. Running such a network for the first time, we will see that the answer is far from correct, because the network is not trained. To improve the results, we will train her. But before we learn how to do this, let's introduce a few terms and properties of a neural network.
Activation function
An activation function is a way to normalize the input (we've talked about this before). That is, if you have a large number at the input, passing it through the activation function, you will get an output in the range you need. There are a lot of activation functions, so we will consider the most basic ones: Linear, Sigmoid (Logistic) and Hyperbolic tangent. Their main difference is the range of values.Linear function
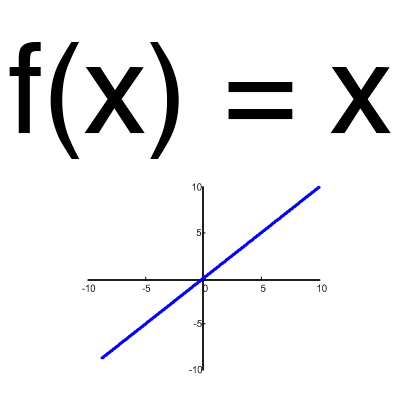
This function is almost never used, except when you need to test a neural network or pass a value without transformations.
Sigmoid

This is the most common activation function, its range of values is . It shows most of the examples on the web, and is also sometimes called the logistic function. Accordingly, if in your case there are negative values (for example, stocks can go not only up, but also down), then you need a function that captures negative values as well.
Hyperbolic tangent

It only makes sense to use hyperbolic tangent when your values can be both negative and positive, since the range of the function is [-1,1]. It is not advisable to use this function only with positive values, as this will significantly worsen the results of your neural network.
Training set
A training set is a sequence of data that a neural network operates on. In our case of exclusive or (xor) we have only 4 different outcomes, that is, we will have 4 training sets: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.Iteration
This is a kind of counter that increases every time the neural network goes through one training set. In other words, this is the total number of training sets passed by the neural network.Epoch
When initializing the neural network, this value is set to 0 and has a manual ceiling. The longer the epoch, the better the network is trained and, accordingly, its result. The epoch increases every time we go through the entire set of training sets, in our case, 4 sets or 4 iterations.
Important do not confuse iteration with epoch and understand the sequence of their increment. First n
once the iteration increases, and then the epoch and not vice versa. In other words, you cannot first train a neural network on only one set, then on another, and so on. You need to train each set once per era. So, you can avoid errors in calculations.
Mistake
Error is a percentage that reflects the discrepancy between expected and received responses. The error is formed every epoch and should decline. If it doesn't, then you're doing something wrong. The error can be calculated in different ways, but we will consider only three main methods: Mean Squared Error (hereinafter referred to as MSE), Root MSE and Arctan. There is no restriction on usage like there is in the activation function, and you are free to choose whichever method gives you the best results. One has only to take into account that each method counts errors differently. With Arctan, the error will almost always be larger, since it works on the principle that the larger the difference, the larger the error. The Root MSE will have the smallest error, so the most commonly used MSE is the one that keeps the balance in the error calculation.In the first half of 2016, the world heard about a lot of developments in the field of neural networks - Google (a network-player in AlphaGo), Microsoft (a number of services for image identification), startups MSQRD, Prisma and others demonstrated their algorithms.
To bookmarks
The editors of the site tell what neural networks are, what they are for, why they captured the planet right now, and not years earlier or later, how much you can earn on them and who are the main market players. Experts from the Moscow Institute of Physics and Technology, Yandex, Mail.Ru Group and Microsoft also shared their opinions.
What are neural networks and what tasks they can solve
Neural networks are one of the directions in the development of artificial intelligence systems. The idea is to model as closely as possible how the human nervous system works - namely, its ability to learn and correct errors. This is the main feature of any neural network - it is able to independently learn and act on the basis of previous experience, each time making fewer and fewer errors.
The neural network imitates not only the activity, but also the structure of the human nervous system. Such a network consists of a large number of individual computational elements (“neurons”). In most cases, each "neuron" refers to a specific layer of the network. The input data is sequentially processed at all layers of the network. The parameters of each "neuron" can change depending on the results obtained on previous sets of input data, thus changing the order of the entire system.
Andrey Kalinin, head of Mail.ru Search at Mail.Ru Group, notes that neural networks are capable of solving the same problems as other machine learning algorithms, the difference lies only in the approach to learning.
All tasks that neural networks can solve are somehow related to learning. Among the main areas of application of neural networks are forecasting, decision making, pattern recognition, optimization, data analysis.
Vlad Shershulsky, director of technology cooperation programs at Microsoft in Russia, notes that neural networks are now used everywhere: “For example, many large Internet sites use them to make the reaction to user behavior more natural and useful to their audience. Neural networks underlie most modern speech recognition and synthesis systems, as well as image recognition and processing. They are used in some navigation systems, whether they are industrial robots or unmanned vehicles. Algorithms based on neural networks protect information systems from attacks by intruders and help identify illegal content on the network.”
In the short term (5-10 years), Shershulsky believes, neural networks will be used even more widely:
Imagine an agricultural harvester with multiple video cameras in its actuators. He takes five thousand pictures per minute of each plant in the strip of his trajectory and, using a neural network, analyzes whether it is a weed, whether it is affected by a disease or pests. And treats each plant individually. Fiction? Not really anymore. And in five years it may become the norm. - Vlad Shershulsky, Microsoft
Mikhail Burtsev, Head of the Laboratory of Neural Systems and Deep Learning at the MIPT Center for Living Systems, gives a tentative map of the development of neural networks for 2016-2018:
- systems for recognition and classification of objects in images;
- voice interaction interfaces for the Internet of things;
- systems for monitoring the quality of service in call centers;
- systems for detecting problems (including predicting the time of maintenance), anomalies, cyber-physical threats;
- intellectual security and monitoring systems;
- replacement by bots of part of the functions of call center operators;
- video analytics systems;
- self-learning systems that optimize the management of material flows or the location of objects (in warehouses, transport);
- intelligent, self-learning control systems for production processes and devices (including robotic ones);
- the emergence of universal translation systems "on the fly" for conferences and personal use;
- the emergence of bots-advisers of technical support or personal assistants, in terms of functions close to a person.
Grigory Bakunov, director of technology dissemination at Yandex, believes that the ability of such systems to make various decisions will become the basis for the spread of neural networks in the next five years: “The main thing that neural networks do for a person now is to save him from excessive decision-making. So they can be used almost anywhere where not too intelligent decisions are made by a living person. In the next five years, it is this skill that will be exploited, which will replace human decision making with a simple machine.”
Why neural networks have become so popular right now
Scientists have been developing artificial neural networks for over 70 years. The first attempt to formalize a neural network dates back to 1943, when two American scientists (Warren McCulloch and Walter Pitts) presented an article on the logical calculus of human ideas and neural activity.
However, until recently, says Andrey Kalinin from Mail.Ru Group, the speed of neural networks was too low for them to be widely used, and therefore such systems were mainly used in developments related to computer vision, and other algorithms were used in other areas. machine learning.
A laborious and time-consuming part of the process of developing a neural network is its training. In order for the neural network to be able to correctly solve the tasks set, it is required to “run” its work on tens of millions of input data sets. It is with the advent of various accelerated learning technologies that Andrey Kalinin and Grigory Bakunov associate the spread of neural networks.
The main thing that has happened now is that various tricks have appeared that allow you to make neural networks that are much less prone to overfitting. - Grigory Bakunov, Yandex
“Firstly, a large and publicly available array of marked-up images (ImageNet) has appeared, on which you can learn. Secondly, modern video cards make it possible to train and use neural networks hundreds of times faster. Thirdly, ready-made, pre-trained neural networks appeared, recognizing images, on the basis of which you can create your own applications without having to do long-term preparation of the neural network for work. All this provides a very powerful development of neural networks in the field of pattern recognition,” Kalinin notes.
What are the market sizes of neural networks
“Very easy to calculate. You can take any area that uses low-skilled labor - call center operators, for example - and simply subtract all human resources. I would say that we are talking about a multi-billion dollar market, even within a single country. How many people in the world are involved in low-skilled work can be easily understood. So even very abstractly speaking, I think we are talking about a hundred billion dollar market all over the world,” says Grigory Bakunov, director of technology distribution at Yandex.
According to some estimates, more than half of professions will be automated - this is the maximum amount by which the market for machine learning algorithms (and neural networks in particular) can be increased. - Andrey Kalinin, Mail.Ru Group
“Machine learning algorithms are the next step in the automation of any processes, in the development of any software. Therefore, the market at least coincides with the entire software market, but rather surpasses it, because it becomes possible to make new intelligent solutions that are inaccessible to old software,” continues Andrey Kalinin, head of Mail.ru Search at Mail.Ru Group.
Why Neural Network Developers Create Mobile Apps for the Mass Market
In the past few months, several high-profile entertainment projects using neural networks have appeared on the market at once - this is the popular video service, which is the social network Facebook, and Russian applications for image processing (in June, investments from Mail.Ru Group) and others.
The abilities of their own neural networks were also demonstrated by Google (AlphaGo technology won the champion in Go; in March 2016, the corporation sold 29 paintings drawn by neural networks and so on at auction), and Microsoft (the CaptionBot project, which recognizes images in pictures and automatically generates captions for them ; the WhatDog project, which determines the breed of a dog from a photograph; the HowOld service, which determines the age of a person in a picture, and so on), and Yandex (in June, the team built a service for recognizing cars in pictures into the Avto.ru application; presented a musical album; in May she created the LikeMo.net project for drawing in the style of famous artists).
Such entertainment services are created rather than to solve global problems that neural networks are aimed at, but to demonstrate the capabilities of a neural network and conduct its training.
“Games are a characteristic feature of our behavior as a biological species. On the one hand, almost all typical scenarios of human behavior can be modeled on game situations, and on the other hand, game creators and, especially, players can get a lot of pleasure from the process. There is also a purely utilitarian aspect. A well-designed game not only brings satisfaction to the players: they train the neural network algorithm as they play. After all, neural networks are based on learning by examples, ”says Vlad Shershulsky from Microsoft.
“First of all, this is done in order to show the possibilities of technology. There is really no other reason. If we are talking about Prisma, then it is clear why they did it. The guys built some pipeline that allows them to work with pictures. To demonstrate this, they have chosen a fairly simple way of creating stylizations. Why not? This is just a demonstration of how the algorithms work,” says Grigory Bakunov from Yandex.
Andrey Kalinin from Mail.Ru Group has a different opinion: “Of course, this is spectacular from the point of view of the public. On the other hand, I would not say that entertainment products cannot be applied to more useful areas. For example, the task of styling images is extremely relevant for a number of industries (design, computer games, animation - just a few examples), and the full use of neural networks can significantly optimize the cost and methods of creating content for them.
Major players in the neural network market
As Andrei Kalinin notes, by and large, most of the neural networks on the market are not much different from each other. “Technology is about the same for everyone. But the use of neural networks is a pleasure that not everyone can afford. To train a neural network on your own and run a lot of experiments on it, you need large training sets and a fleet of machines with expensive video cards. Obviously, large companies have such opportunities,” he says.
Among the main market players, Kalinin mentions Google and its division Google DeepMind, which created the AlphaGo network, and Google Brain. Microsoft has its own developments in this area - they are handled by the Microsoft Research laboratory. Neural networks are being created at IBM, Facebook (a division of Facebook AI Research), Baidu (Baidu Institute of Deep Learning) and others. Many developments are carried out at technical universities around the world.
Grigory Bakunov, director of technology dissemination at Yandex, notes that interesting developments in the field of neural networks are also found among startups. “I would remember, for example, ClarifAI. This is a small startup, once made by people from Google. Now they are probably the best in the world at identifying the content of a picture.” These startups include MSQRD, Prisma, and others.
In Russia, developments in the field of neural networks are carried out not only by startups, but also by large technology companies - for example, the Mail.Ru Group holding uses neural networks for processing and classifying texts in the "Search", image analysis. The company also conducts experimental developments related to bots and conversational systems.
Yandex is also creating its own neural networks: “Basically, such networks are already used in working with images, with sound, but we are exploring their capabilities in other areas. Now we are doing a lot of experiments in the use of neural networks in working with text.” Development is carried out at universities: at Skoltech, Moscow Institute of Physics and Technology, Moscow State University, Higher School of Economics and others.
This time I decided to study neural networks. I was able to get basic skills in this matter during the summer and autumn of 2015. By basic skills, I mean that I can create a simple neural network myself from scratch. You can find examples in my GitHub repositories. In this article, I will give some clarifications and share resources that you may find useful for your study.
Step 1: Neurons and Feedforward Propagation
So what is a "neural network"? Let's wait with this and deal with one neuron first.
A neuron is like a function: it accepts multiple inputs and returns one.
The circle below represents an artificial neuron. It receives 5 and returns 1. The input is the sum of the three synapses connected to the neuron (three arrows on the left).
On the left side of the picture we see 2 input values (in green) and an offset (highlighted in brown).
The input data can be numerical representations of two different properties. For example, when creating a spam filter, they could mean having more than one word written in CAPITAL LETTERS and having the word "Viagra".
The input values are multiplied by their so-called "weights", 7 and 3 (highlighted in blue).
Now we add the resulting values with the offset and get a number, in our case 5 (highlighted in red). This is the input of our artificial neuron.

Then the neuron performs some kind of calculation and produces an output value. We got 1 because the rounded value of the sigmoid at point 5 is 1 (more on this function later).
If this were a spam filter, the fact that the output is 1 would mean that the text was marked as spam by the neuron.

Neural network illustration from Wikipedia.
If you combine these neurons, you get a forward-propagating neural network - the process goes from input to output, through neurons connected by synapses, as in the picture on the left.
Step 2. Sigmoid
After you've watched the Welch Labs tutorials, it's a good idea to check out the fourth week of the Coursera machine learning course on neural networks to help you understand how they work. The course goes deep into math and is based on Octave, while my preference is Python. Because of this, I skipped the exercises and got all the necessary knowledge from the video.

Sigmoid simply maps your value (on the horizontal axis) to a segment from 0 to 1.
The first priority for me was to study the sigmoid, as it figured in many aspects of neural networks. I already knew something about her from the third week of the above course, so I reviewed the video from there.
But videos alone won't take you far. For a complete understanding, I decided to code it myself. So I started writing an implementation of the logistic regression algorithm (which uses sigmoid).
It took a whole day, and the result is unlikely to be satisfactory. But it doesn't matter, because I figured out how everything works. The code can be seen.
You don't have to do it yourself, because it requires special knowledge - the main thing is that you understand how the sigmoid works.
Step 3 Back Propagation Method
Understanding how a neural network works from input to output is not that difficult. It is much more difficult to understand how a neural network is trained on datasets. The principle I used is called
Neural networks are one of the areas of research in the field of artificial intelligence, based on attempts to reproduce the human nervous system. Namely: the ability of the nervous system to learn and correct errors, which should allow us to model, albeit rather crudely, the work of the human brain.
or the human nervous system is a complex network of human structures that ensures the interconnected behavior of all body systems.A biological neuron is a special cell that structurally consists of a nucleus, a cell body and processes. One of the key tasks of a neuron is to transmit an electrochemical impulse throughout the neural network through available connections with other neurons. Moreover, each connection is characterized by a certain value, called the strength of the synaptic connection. This value determines what happens to the electrochemical impulse when it is transmitted to another neuron: either it will increase, or it will weaken, or remain unchanged.
A biological neural network has a high degree of connectivity: one neuron can have several thousand connections with other neurons. But, this is an approximate value and in each case it is different. The transmission of impulses from one neuron to another generates a certain excitation of the entire neural network. The magnitude of this excitation determines the response of the neural network to some input signals. For example, a meeting of a person with an old acquaintance can lead to a strong excitation of the neural network if some vivid and pleasant life memories are associated with this acquaintance. In turn, a strong excitation of the neural network can lead to an increase in heart rate, more frequent blinking of the eyes, and other reactions. Meeting with a stranger for the neural network will be almost imperceptible, and therefore will not cause any strong reactions.
The following highly simplified model of a biological neural network can be given:

Each neuron consists of a cell body, which contains a nucleus. Many short fibers called dendrites branch off from the cell body. Long dendrites are called axons. The axons are stretched over great distances, far beyond what is shown to scale in this figure. Typically, axons are 1 cm long (which is 100 times the diameter of the cell body), but can be as long as 1 meter.
In the 60-80s of the XX century, the priority direction of research in the field of artificial intelligence was. Expert systems have proven themselves, but only in highly specialized areas. To create more versatile intelligent systems, a different approach was required. Perhaps this has led artificial intelligence researchers to turn their attention to the biological neural networks that underlie the human brain.
Neural networks in artificial intelligence are simplified models of biological neural networks.
This is where the similarity ends. The structure of the human brain is much more complex than that described above, and therefore it is not possible to reproduce it at least more or less accurately.
Neural networks have many important properties, but the key one is the ability to learn. Training a neural network primarily consists in changing the “strength” of synaptic connections between neurons. The following example clearly demonstrates this. In Pavlov's classic experiment, each time a bell rang just before feeding the dog. The dog quickly learned to associate the ringing of a bell with eating. This was due to the fact that the synaptic connections between the parts of the brain responsible for hearing and the salivary glands increased. And subsequently, excitation of the neural network by the sound of the bell began to lead to stronger salivation in the dog.
Today, neural networks are one of the priority areas of research in the field of artificial intelligence.
Neural networks are a mathematical model built on the basis of the principles of operation of bionic neural networks. Acquaintance with this phenomenon should begin with the concept of a multilayer perceptron as the first embodiment of this system as a computer model.
What is a multilayer perceptron in brief
A multilayer perceptron is a hierarchical computational model where the calculator is built from a set of neurons of simple nodes that have many inputs and one output. Each input (synapse) has a weight associated with it.
The inputs of the system are supplied with values that propagate through interneuronal connections. These values, which are real numbers, are multiplied by the link weights.
The logical diagram of the principle of the perceptron's functioning is most easily represented using a graphical drawing with different colors and connections between them:
Using neural networks
This method is used for a variety of purposes. For example, if you submit securities quotes on the stock exchange as an input, then the resulting result can be interpreted as a signal that the security will fall in price or rise in price in the future.
Another example of the future use of neural networks is the more accurate prediction of global and financial recessions.
If the input is given, for example, the brightness value of the set of raster dots, then at the output you can get a decision about what the picture is.
According to this scheme, neural networks have learned to imitate the paintings of famous artists, including Van Gogh, as well as draw unique images themselves in a wide variety of artistic styles.
For such a significant achievement in the development of neural networks, the term was proposed by Google inceptionism - painting created by artificial intelligence and characterized by extreme psychedelic in the best traditions.

Of course, in order for the system to give the correct answers, it is necessary to fine-tune it. Initially, the principle of operation was based on a randomized selection of random variables. Therefore, the essence of the algorithm is to adjust the system to the most correct answers.
For this purpose, the neural network structure was supplemented with a weight correction algorithm, which allows minimizing errors. This is an extremely useful thing that has been documented many times over with many commercial products.
However, paradoxically, the system still did not become similar to the human brain. It became clear that in order to solve problems more serious than the exchange forecast, for example, for a complex robot control system with multimodal information, the neural network must be large, while traditional neural networks are difficult to make like that.
The fact is that the brain consists of 10 billion neurons, each of which has 10,000 connections. This is an extremely energy-efficient and noise-resistant system, created over millions of years. What is the difference?
Differences in the principle of operation of the brain and neural networks
It's all about the different principle of signal transmission of our biological network of neurons and perceptron. In a multilayer perceptron, neurons exchange values with each other, which are real numbers. And in the brain there is an exchange of impulses with a strictly fixed amplitude and short duration. That is, the pulses are almost instantaneous.
A whole range of advantages and benefits follows from this. Firstly, such signal lines are very economical and inactive - almost nothing propagates through the connections between neurons. In the perceptron, each signal line must carry a really significant value.
Secondly, the pulse signal transmission scheme, along with energy efficiency, also provides ease of implementation, since the generation and processing of pulses can be carried out using the simplest analog circuits, in contrast to complex machinery to support the transfer of real values.
Thirdly, impulse (spike) networks are protected from interference. We have a calibrated impulse, the imposition of noise on which does not interfere with the operation of the system. Real numbers, on the other hand, are affected by noise.
And, of course, if we talk about numerical simulation with digital rather than analog transmission, then to encode 1 byte of information, we need 8 signal lines instead of one.
That is, the digital implementation of such systems is also not an option. Even installing multi-layer routers does not solve the problem, as the neural network slows down and continues to be inefficient.
Therefore, it is obvious that to create large-scale neural networks, a bionic approach should be used, namely, trying to create a system in the image and likeness of the brain.
We will talk about this most interesting class of impulse neural networks further:
Video on the topic of the essence of neural networks in simple language: